The ultimate free solution, parse any CSV file to a JSON Array via a Power Automate Flow. This flow will parse any CSV file, no matter the encoding. It will handle Unix, Windows, or Mac files. The key values (i.e. the header row) will be dynamically mapped and it will handle CSV files of all shapes and sizes. Whilst I have previously blogged about parsing an array with a select action, this solution did not handle varying header lengths automatically.
The solution below will automatically handle the following:
- multiple sources within O365: OneDrive, SharePoint, or Outlook
- common file encodings (Unix, Windows & Mac)
- varying header sizes
- and most importantly it is free for you to use and copy
What does the Flow look like? The Pseudo Code
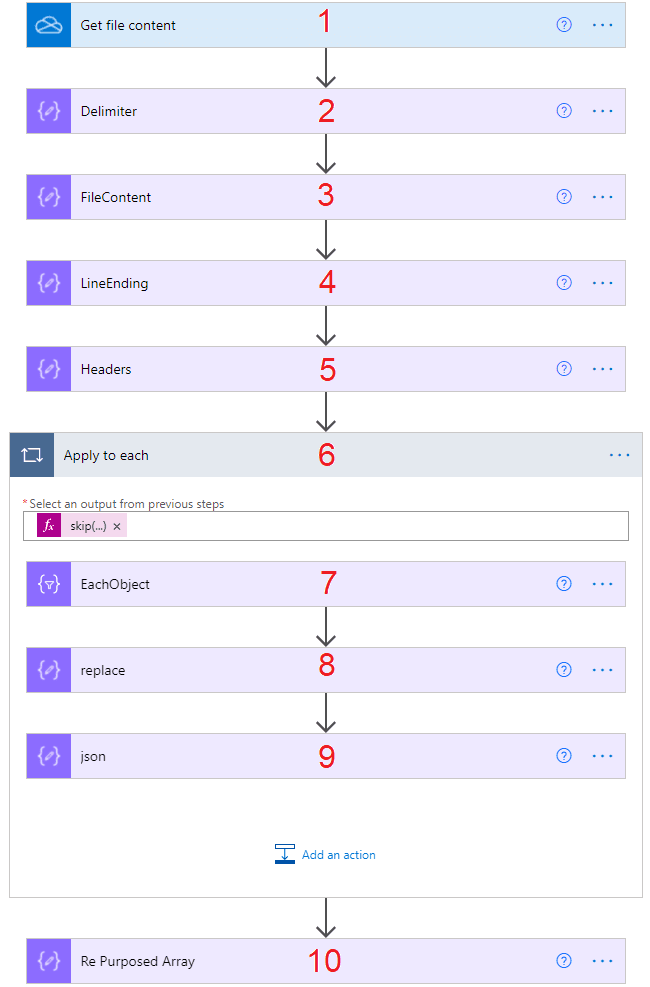
- Get File Content, this action is for OneDrive where data is actually returned as a string. I will also cover SharePoint and email data sources below. These data sources need to convert from Base64 Encoding to String.
- Compose (Delimiter), this is a parameter, leave unchanged as a comma ,. If you want to parse a pipe-delimited or semi colon-delimited, change as appropriate | or ;
- Compose (FileContent), this is for returning the file content of the Get File Content action. I also took the opportunity to replace quotes with an empty string. This is to cater for quote encapsulated CSV’s. Note that strings containing the separator will cause problems aligning the values/columns. I suggest you watch the following video here on a possible solution.
- Compose (LineEnding), allows an expression to check for the appearance of one of three return chars. 0d0a, 0a, or 0d, and setting the value as appropriate.
- Compose (Headers), use a split expression, and the LineEnding on the first element of the file content. Then split again using the Delimiter. We create an array of header values to be used as keys in the Apply to Each action.
- Apply To Each, skip the header, and split the Array using the LineEnding. Each loop is passed an array of row items. I have turned on concurrency for maximum efficiency.
- Select (EachObject), we create a range from 0 to header array length. The header/key is mapped by calling each element by an integer. We return the value by splitting the row by our Delimiter. As before, we return the value by using an integer. You can watch how we might call array elements by integer here.
- Select (Replace), we want to work with an object at this point. We convert the Array to a string and replace the curly brackets { and } with an empty string ‘’. We do the same with the square brackets [ and ] into curly brackets { and }.
- Compose (json), we run the new string through the JSON expression. This eliminates any escaped strings for our final array.
- Compose (Re Purposed Array), finally, we’ve made it (!). Outside of the apply to each, we can bring our objects together and create our re-purposed Array.
Flow Actions in More Detail
Below I have split the flow into two parts. The first demonstrates the data preparation. Defining the delimiter, preparing the file content, identifying the LineEnding and splitting the headers. Each of the expressions used are in the comments but also available below to copy and paste.

3. FileContent: replace(outputs('Get_file_content')?['body'],'"','')
4. LineEnding: if(equals(indexof(outputs('FileContent'), decodeUriComponent('%0D%0A')), -1), if(equals(indexof(outputs('FileContent'), decodeUriComponent('%0A')), -1), decodeUriComponent('%0D'), decodeUriComponent('%0A')), decodeUriComponent('%0D%0A'))
5. Headers: split(first(split(outputs('FileContent'),outputs('LineEnding'))),outputs('Delimiter'))
The second part of the solution is the apply to each. For each of the rows in the CSV we map out each of the the keys (i.e the header) and value (the column data values). We then convert the array returned by the Select into an Object. The json expression removes any escaped characters i.e. ". This enables the final action to bring the objects back together as an Array.

6. Apply to Each: skip(split(outputs('FileContent'),outputs('LineEnding')),1)
7. Each Object:
FROM: range(0, length(outputs('Headers')))
KEY: outputs('Headers')?[item()]
VALUE: split(items('Apply_to_each'),outputs('Delimiter'))?[item()]
8. Replace: replace(replace(replace(replace(string(body('EachObject')), '{', ''), '}', ''), '[', '{'), ']', '}')
9. JSON: json(outputs('replace'))
10. Re-Purposed Array: outputs('json')
The Input vs Output
The advantage of retrieving file content from OneDrive is that it is returned as a string. Remember that this solution does not need you to specify the header keys. It works them out dynamically. If you have ten columns in the CSV, you will get ten keys in your array. If you change the file structure, it will map it immediately to fit the new file layout.
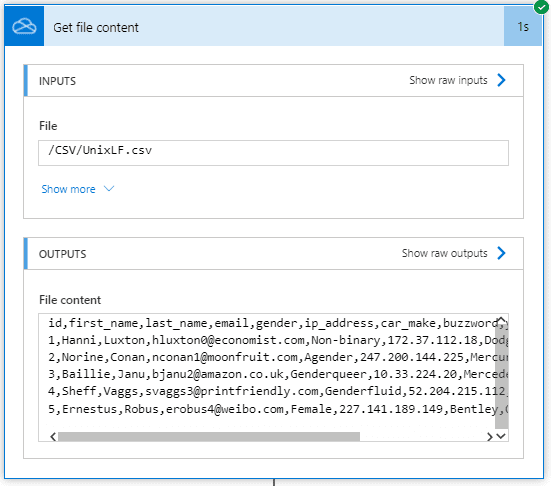
The final action of the Flow will return a perfectly formatted JSON Array. Note that the column headers have been applied to the keys.

You can now call any of the keys by building up an expression. For example, to return first_name Hanni, you would use the following:
first(outputs('Re_Purposed_Array'))?['first_name']
OR
outputs('Re_Purposed_Array')?[0]?['first_name']
If you wanted to return all of the email addresses in an array so that you can send an email to all of the users, you could use a select action. Watch here to see this in action.
Other file sources, SharePoint and Outlook
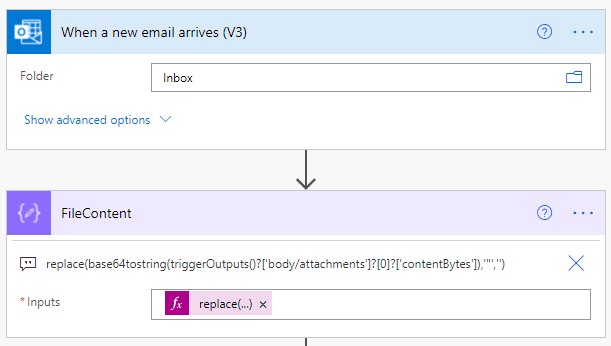
For both SharePoint and Outlook, the file is retrieved in Base64. You need to use the expression Base64toString. After this has been performed, the actions of the flow are identical. You will recall that I used a compose called FileContent. If you replace the file content with the SharePoint or Outlook source (Including the replace), the Flow will operate exactly the same with minimal disruption.
In order to Get file content from SharePoint, you build an expression to select the $content from the body. Remember that we must convert from Base64 to string.

When an email is received in your Mailbox with A CSV attachment, convert the Base64 encoded attachment contentBytes to string and replace the double quotes with an empty string.
Want to understand File Encodings?
It is interesting to understand the return characters for the file encodings in Unix, Windows, and Mac files. Rather than repeat what is already out there, please read up on Wikipedia here if you are interested in learning more. I have highlighted the difference pictorially below for the more common encodings, Windows and Unix. My Flow handles all three encodings automatically via the use of the IndexOf expression, if one encoding doesn’t appear in the file contents, it will check for the other types.
Windows File Encoding with 0dx0a Line Break
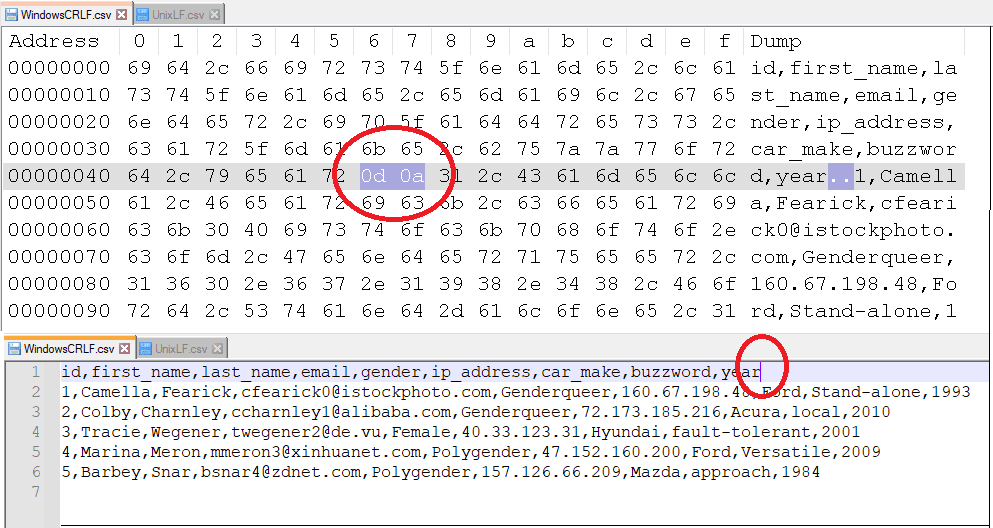
Side by side - Windows Encoded CSV with ASCII vs Hex - 0dx0a Line Break
Unix File Encoding with 0a Line Break
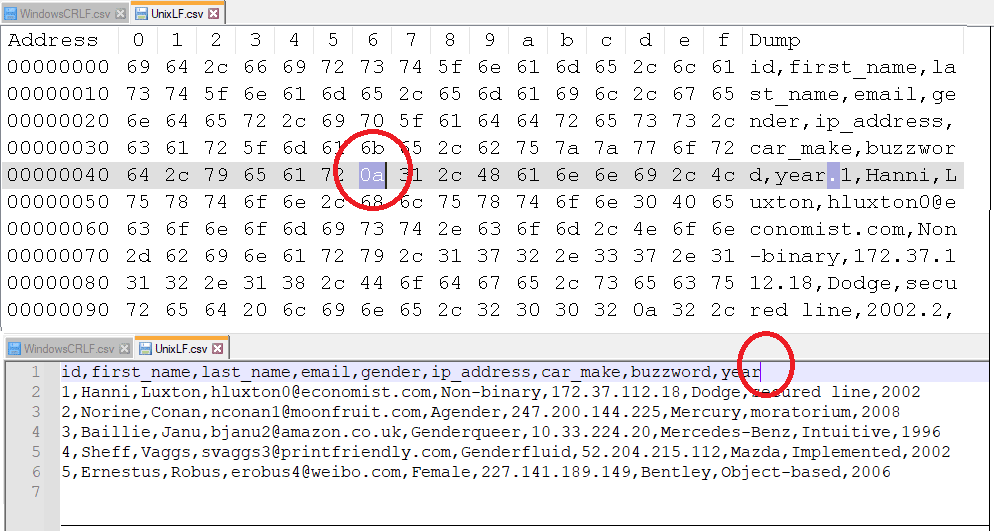
Side by side - Unix Encoded CSV with ASCII vs Hex - 0a Line Break
And finally….
There are paid-for actions out there to do this for you, for example, Encodian. There are also a few other ways of doing this. What can you learn from them?
- Power Automate: How to parse a CSV File to create a JSON array (Paulie Murana)
- Power Automate: How to parse a CSV file (Manuel Gomes)
- 3 steps to read csv files from SharePoint (Pieter Veenstra)
This solution covers a multitude of expressions and actions. It demonstrates how you can parse most, if not all CSV files to a JSON Array without the need to consider the size and shape of the Array. The headers and column sizes will be handled dynamically, As demonstrated, the source can be OneDrive, SharePoint or via attachments in Outlook.
A couple of discoveries from testing, some files contain byte order marking or BOM and so you might need to replace EF BB BF for an empty string if you see any strange characters at the beginning of your file. I’ve also noticed that some arrays contain an empty final object. This object could be skipped using a filter array where the object is empty. I’ve left you to explore this for yourself.