Got a CSV file you need to turn into a JSON array in Power Automate — without premium connectors? In this post, I’ll share a copy-and-paste Select Action that does exactly that. Just paste it into your flow, adjust the columns, and you’re done — no Apply to Each loops required. I’ve recently covered how to efficiently parse a CSV here vs the age-old apply to each solution.
Updated Solution Available
Note, that I now have an ever more improved parsing solution. Handle the column keys dynamically. Any shape or sized CSV without the need to edit the existing flow. Retrieve data from OneDrive, SharePoint and Outlook Attachements.
See how it works on multiple CSV files to JSON Array conversions
CSV to JSON using my ready made solution pasted into your Cloud Flow
Understanding CSV Encoding
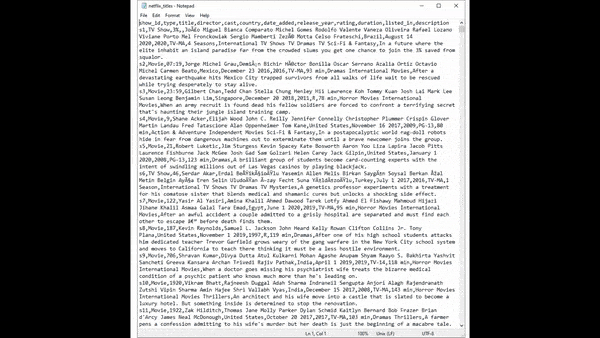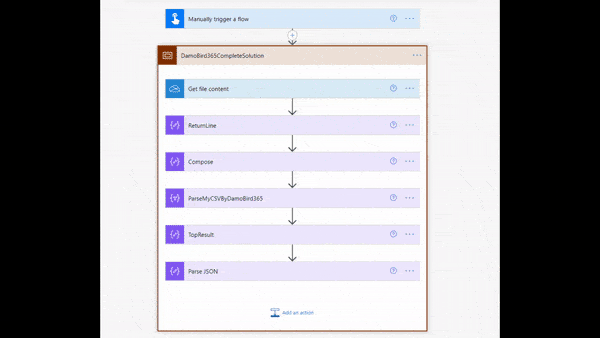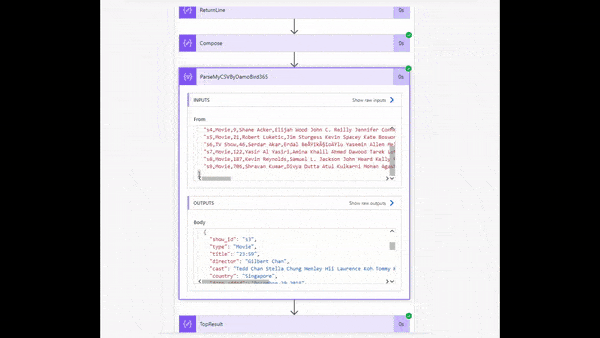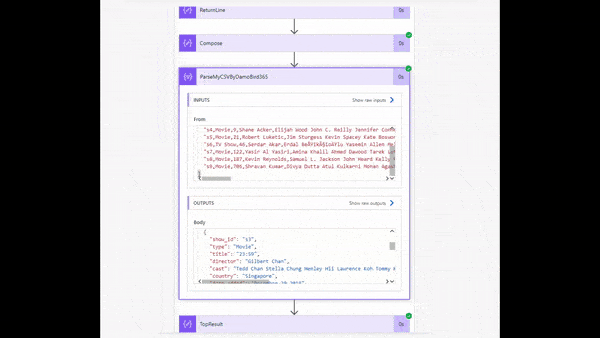
I’ve just downloaded a CSV from Kaggle and it contains all Netflix Shows with 12 columns of data. I will show you how I parsed this data really fast. Something to note is how the CSV is encoded. Linux files use \n as a new line whereas Windows uses \r\n to indicate a return and new line. For the purpose of this demo I am using linux encoded \n files and am therefore able to use a compose with a return line. If you are using files with \r\n you will have to follow my article here and make a slight change to my sample code it’s important to understand how your CSV is encoded.

Sample CSV Data for Netflix
Building the Flow — Establishing the Array
The first part of the Cloud Flow is to establish an Array of the CSV data. The easiest method is to use the Get File Content action for One Drive as it returns the file as plain text, use the SharePoint Get File and you must re-encode the file content. Then in order to split the lines I create a Compose Action “ReturnLine” which simply has a single return line (that’s right, insert your cursor and hit return). The final step is a compose action that you split the file content by the ReturnLine Compose action.
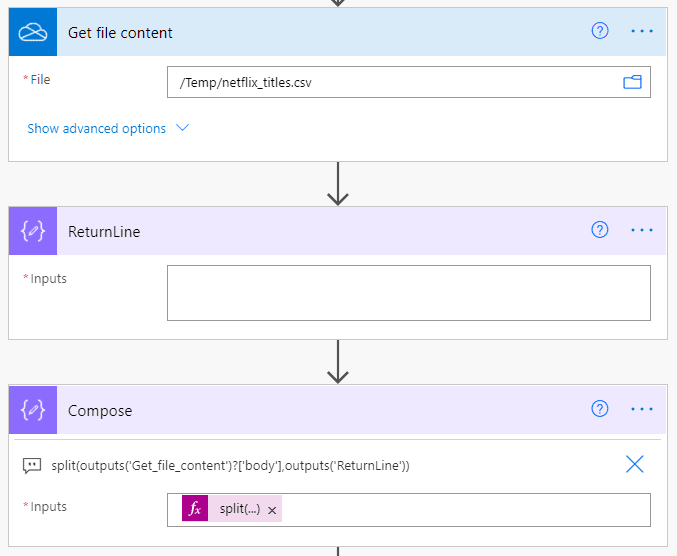
The start of the flow to establish an Array
The Copy-Paste Select Action
The next part of the process is the clever part. I have devised a copy/paste option. Assuming that you have a header in the file like my sample NetFlix data above, you can copy and paste my sample select action into your Cloud Flow and add/remove any additional columns as you see fit. My example has twelve columns and in this case I have supplied a sample action with 12 keys and values built up using split and choosing elements by integer numbers.
Paste the sample code into My Clipboard
Upon Selecting the pasted action “ParseMyCSVByDamoBird365” into Power Automate you will see the pre-populated Action below:

Prepopulated Select Action
Sample Code
Here is the sample code:
{
"id": "DamoBird365",
"brandColor": "#8C6CFF",
"connectorDisplayName": "Data Operations",
"isTrigger": false,
"operationName": "ParseMyCSVByDamoBird365",
"operationDefinition": {
"type": "Select",
"inputs": {
"from": "@skip(outputs('Compose'),1)",
"select": {
"@{split(first(outputs('Compose')),',')?[0]}": "@split(item(),',')?[0]",
"@{split(first(outputs('Compose')),',')?[1]}": "@split(item(),',')?[1]",
"@{split(first(outputs('Compose')),',')?[2]}": "@split(item(),',')?[2]",
"@{split(first(outputs('Compose')),',')?[3]}": "@split(item(),',')?[3]",
"@{split(first(outputs('Compose')),',')?[4]}": "@split(item(),',')?[4]",
"@{split(first(outputs('Compose')),',')?[5]}": "@split(item(),',')?[5]",
"@{split(first(outputs('Compose')),',')?[6]}": "@split(item(),',')?[6]",
"@{split(first(outputs('Compose')),',')?[7]}": "@split(item(),',')?[7]",
"@{split(first(outputs('Compose')),',')?[8]}": "@split(item(),',')?[8]",
"@{split(first(outputs('Compose')),',')?[9]}": "@split(item(),',')?[9]",
"@{split(first(outputs('Compose')),',')?[10]}": "@split(item(),',')?[10]",
"@{split(first(outputs('Compose')),',')?[11]}": "@split(item(),',')?[11]"
}
},
"runAfter": {
"Compose": ["Succeeded"]
}
}
}
How the Select Action Works
The from of the Select Action is made up of the original array, minus the first line (header). I do this by calling the Skip Expression.
The key is made up of the first line of the Array, split by a comma to make an array and each element is chosen by an integer, starting from 0.
The value is made up with a split by a comma on each item to make an array and each element is chosen by an integer, starting from 0.
**NOTE** as an example - if you have 5 header items in your CSV, simply remove the additional lines from the Select Action to leave 0->4.
I have uploaded a cleansed version of the Netflix CSV for you to try here or a simplified 10 row version here. Let me know how you get on.
Pro Tips
Have you tried copying actions and then editing them in a text editor? Did you know that you can do this? Another quick tip is to put all of your actions into a scope and paste them into your next flow. Now you can easily copy large parts of existing flows into new flows!
More great ideas and tips here, don’t forget to bookmark and subscribe to my YouTube channel.
Complete Solution — Ready to Paste
Want it easy? Try copying and pasting the following where I have also included the schema to use the bespoke column dynamic data:
{
"id": "54b0c051-85b3-4d6f-9232-b037-16b336d3",
"brandColor": "#8C3900",
"connectionReferences": {
"shared_onedriveforbusiness": {
"connection": {
"id": "/providers/Microsoft.PowerApps/apis/shared_onedriveforbusiness/connections/shared-onedriveforbu-5a107753-9d6f-4fbf-957e-72c6-987acc35"
}
}
},
"connectorDisplayName": "Control",
"icon": "data:image/svg+xml;base64,PHN2ZyB3aWR0aD0iMzIiIGhlaWdodD0iMzIiIHZlcnNpb249IjEuMSIgdmlld0JveD0iMCAwIDMyIDMyIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPg0KIDxwYXRoIGQ9Im0wIDBoMzJ2MzJoLTMyeiIgZmlsbD0iIzhDMzkwMCIvPg0KIDxwYXRoIGQ9Im04IDEwaDE2djEyaC0xNnptMTUgMTF2LTEwaC0xNHYxMHptLTItOHY2aC0xMHYtNnptLTEgNXYtNGgtOHY0eiIgZmlsbD0iI2ZmZiIvPg0KPC9zdmc+DQo=",
"isTrigger": false,
"operationName": "DamoBird365CompleteSolution",
"operationDefinition": {
"type": "Scope",
"actions": {
"Get_file_content": {
"type": "OpenApiConnection",
"inputs": {
"host": {
"connectionName": "shared_onedriveforbusiness",
"operationId": "GetFileContent",
"apiId": "/providers/Microsoft.PowerApps/apis/shared_onedriveforbusiness"
},
"parameters": {
"id": "b!BOIVsACSM02nAvrKA5sQqce2eGDhytpJrD6Ky1g1xl_-qoaIOl6yRo2252_HSDPt.01SRF3RDVKY4JNLOKJOFB3MKKKWQPKLWAP",
"inferContentType": true
},
"authentication": {
"type": "Raw",
"value": "@json(decodeBase64(triggerOutputs().headers['X-MS-APIM-Tokens']))['$ConnectionKey']"
}
},
"runAfter": {},
"metadata": {
"b!BOIVsACSM02nAvrKA5sQqce2eGDhytpJrD6Ky1g1xl_-qoaIOl6yRo2252_HSDPt.01SRF3RDXVNLPLRY4BP5E3JFENUQ7QBRIJ": "/Temp/username-password-recovery-code.csv",
"b!BOIVsACSM02nAvrKA5sQqce2eGDhytpJrD6Ky1g1xl_-qoaIOl6yRo2252_HSDPt.01SRF3RDREN5NIGPEYG5C3DS6WG666PJO7": "/Temp/netflix_titles.csv",
"b!BOIVsACSM02nAvrKA5sQqce2eGDhytpJrD6Ky1g1xl_-qoaIOl6yRo2252_HSDPt.01SRF3RDVKY4JNLOKJOFB3MKKKWQPKLWAP": "/Temp/netflix_titles_small.csv"
}
},
"ReturnLine": {
"type": "Compose",
"inputs": "\n",
"runAfter": {
"Get_file_content": ["Succeeded"]
}
},
"Compose": {
"type": "Compose",
"inputs": "@split(outputs('Get_file_content')?['body'], outputs('ReturnLine'))",
"runAfter": {
"ReturnLine": ["Succeeded"]
},
"description": "split(outputs('Get_file_content')?['body'],outputs('ReturnLine'))"
},
"ParseMyCSVByDamoBird365": {
"type": "Select",
"inputs": {
"from": "@skip(outputs('Compose'), 1)",
"select": {
"@{split(first(outputs('Compose')),',')?[0]}": "@split(item(), ',')?[0]",
"@{split(first(outputs('Compose')),',')?[1]}": "@split(item(), ',')?[1]",
"@{split(first(outputs('Compose')),',')?[2]}": "@split(item(), ',')?[2]",
"@{split(first(outputs('Compose')),',')?[3]}": "@split(item(), ',')?[3]",
"@{split(first(outputs('Compose')),',')?[4]}": "@split(item(), ',')?[4]",
"@{split(first(outputs('Compose')),',')?[5]}": "@split(item(), ',')?[5]",
"@{split(first(outputs('Compose')),',')?[6]}": "@split(item(), ',')?[6]",
"@{split(first(outputs('Compose')),',')?[7]}": "@split(item(), ',')?[7]",
"@{split(first(outputs('Compose')),',')?[8]}": "@split(item(), ',')?[8]",
"@{split(first(outputs('Compose')),',')?[9]}": "@split(item(), ',')?[9]",
"@{split(first(outputs('Compose')),',')?[10]}": "@split(item(), ',')?[10]",
"@{split(first(outputs('Compose')),',')?[11]}": "@split(item(), ',')?[11]"
}
},
"runAfter": {
"Compose": ["Succeeded"]
}
},
"Top5Results": {
"type": "Compose",
"inputs": "@take(body('ParseMyCSVByDamoBird365'),5)",
"runAfter": {
"ParseMyCSVByDamoBird365": ["Succeeded"]
}
},
"Parse_JSON": {
"type": "ParseJson",
"inputs": {
"content": "@body('ParseMyCSVByDamoBird365')",
"schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"show_id": {
"type": "string"
},
"type": {
"type": "string"
},
"title": {
"type": "string"
},
"director": {
"type": "string"
},
"cast": {
"type": "string"
},
"country": {
"type": "string"
},
"date_added": {
"type": "string"
},
"release_year": {
"type": "string"
},
"rating": {
"type": "string"
},
"duration": {
"type": "string"
},
"listed_in": {
"type": "string"
},
"description": {
"type": "string"
}
},
"required": ["show_id", "type", "title", "director", "cast", "country", "date_added", "release_year", "rating", "duration", "listed_in", "description"]
}
}
},
"runAfter": {
"Top5Results": ["Succeeded"]
}
}
},
"runAfter": {}
}
}